La transformación digital y la automatización de procesos en las empresas y en la propia sociedad se ha convertido en una realidad.
En un entorno en que cada vez es más importante la cualificación de los empleados, es necesario establecer estrategias que doten a las empresas de las herramientas necesarias para retener talento. El desafío de conocer las causas o factores que motivan a un empleado a dejar la empresa puede afrontarse utilizando técnicas de machine learning.
En este notebook muestro como he desarrollado una aplicación web que permite hacer una predicción para saber si un empleado va a dejar o no la empresa. La predicción se basa en valores de características que el usuario selecciona por pantalla (puesto en la empresa, sueldo, años trabajados, edad, distancia a casa y horas extra).
La aplicación está desarrollada íntegramente en python sobre un servidor SAP HANA Express XSA. He utilizado una librería de python (hana_ml) que permite leer datos y generar modelos de machine learning directamente en HANA. La página web está desarrollada también en python utilizando streamlit, una librería que permite generar páginas web de forma rápida y sencilla.
Carga y procesado de datos
El modelo generado se basa en un dataset público de datos de empleados de IBM:
https://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset
Dicho dataset incluye información sobre unos 1500 empleados y 35 características entre las que destacan sueldo, edad, sexo, nivel educativo, años en la compañia, puesto en la empresa y un indicador que muestra si el empleado abandonó o no la empresa.
Cargamos el fichero de datos desde un repositorio de github y se procesa la información
import pandas as pd
# Load data from my github public repository
csv_url = "https://raw.githubusercontent.com/alejandromanas/GoogleColab_public/master/HR%20Attrition/WA_Fn-UseC_-HR-Employee-Attrition.csv"
df_pandas = pd.read_csv(csv_url)
# Uppercase columns
df_pandas.columns = df_pandas.columns.str.upper()
# Attrition moved to last column
cols = list(df_pandas.columns.values) #Make a list of all of the columns in the df
cols.pop(cols.index('ATTRITION')) #Remove column from list
df_pandas = df_pandas[cols+['ATTRITION']] #Create new dataframe with columns in the order you want
# New Index column
df_pandas.insert(0, 'ID', df_pandas.reset_index().index)
# Drop columns with one value or useless
df_pandas = df_pandas.drop(["OVER18","EMPLOYEECOUNT","EMPLOYEENUMBER","STANDARDHOURS"],axis=1)import pandas as pd
# Load data from my github public repository
csv_url = "https://raw.githubusercontent.com/alejandromanas/GoogleColab_public/master/HR%20Attrition/WA_Fn-UseC_-HR-Employee-Attrition.csv"
df_pandas = pd.read_csv(csv_url)
# Uppercase columns
df_pandas.columns = df_pandas.columns.str.upper()
# Attrition moved to last column
cols = list(df_pandas.columns.values) #Make a list of all of the columns in the df
cols.pop(cols.index('ATTRITION')) #Remove column from list
df_pandas = df_pandas[cols+['ATTRITION']] #Create new dataframe with columns in the order you want
# New Index column
df_pandas.insert(0, 'ID', df_pandas.reset_index().index)
# Drop columns with one value or useless
df_pandas = df_pandas.drop(["OVER18","EMPLOYEECOUNT","EMPLOYEENUMBER","STANDARDHOURS"],axis=1)Nos conectamos a SAP HANA y cargamos los datos en una tabla para procesar los datos en el servidor
# HANA Connection function
def HanaConn(url,port,usr,pwd):
cc = dataframe.ConnectionContext(url,port,usr,pwd)
#cc.connection.isconnected() is True when connection works
if cc.connection.isconnected() == True:
print ('Connected to HANA')
print('HANA version: ',cc.hana_version())
return cc
# Pandas dataframe is loaded on HANA Table
df_remote = dataframe.create_dataframe_from_pandas(cc1,df_pandas,table_name = 'HR_ATTRITION', schema='PAL',force=True)# HANA Connection function
def HanaConn(url,port,usr,pwd):
cc = dataframe.ConnectionContext(url,port,usr,pwd)
#cc.connection.isconnected() is True when connection works
if cc.connection.isconnected() == True:
print ('Connected to HANA')
print('HANA version: ',cc.hana_version())
return cc
# Pandas dataframe is loaded on HANA Table
df_remote = dataframe.create_dataframe_from_pandas(cc1,df_pandas,table_name = 'HR_ATTRITION', schema='PAL',force=True)Se muestra la información de la tabla generada en HANA
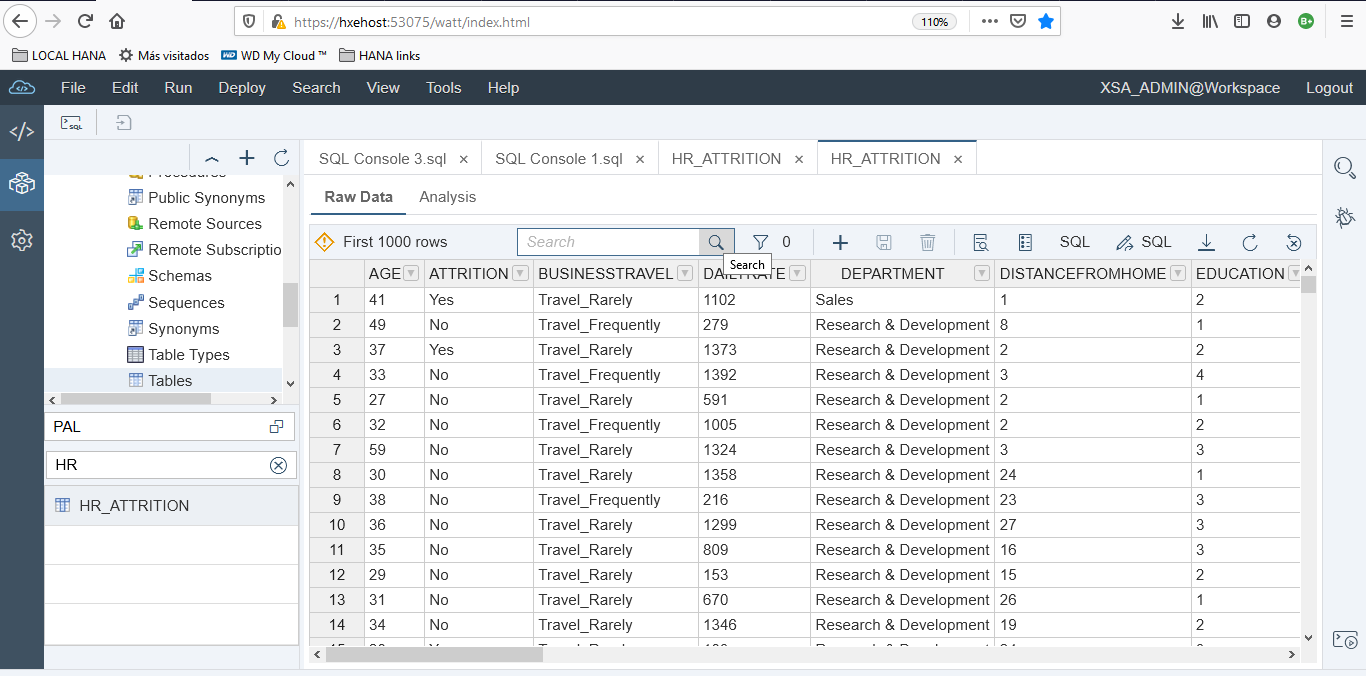
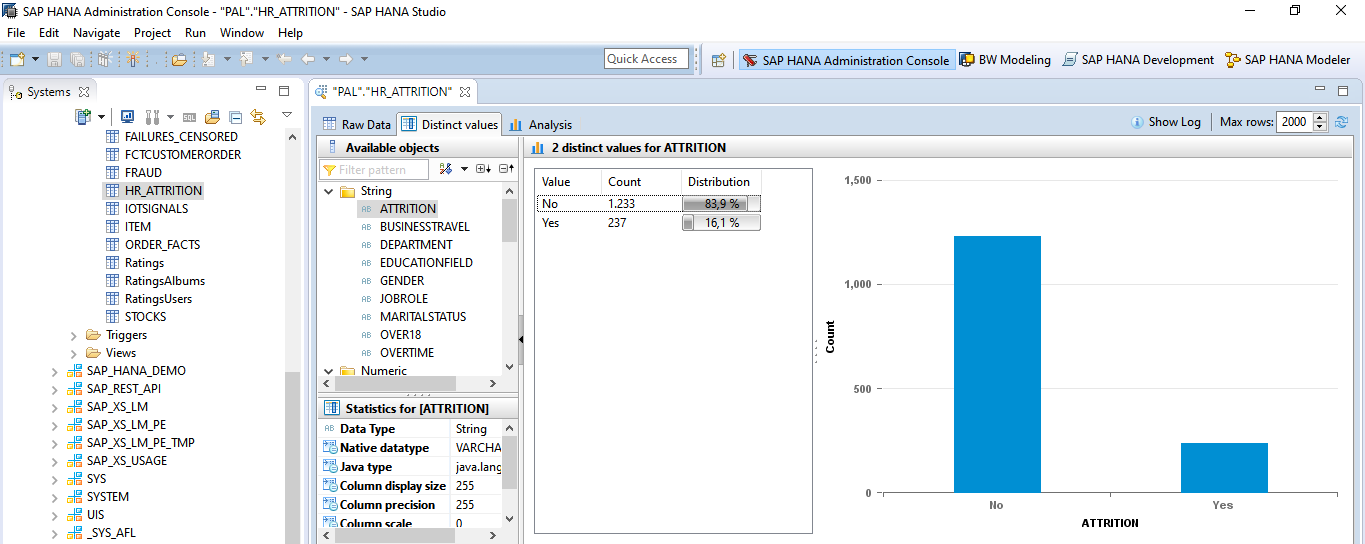
La caracteristica 'ATTRITION' indica si el empleado dejó la empresa (16,1%)
Entrenamiento del modelo
Dividimos los datos en dos grupos: entrenamiento y test
#data partition (70% train, 30% test)
df_train, df_test, df_ignore = partition.train_test_val_split(data = df_remote,
training_percentage = 0.7,
testing_percentage = 0.3,
validation_percentage = 0)
print('train num entries:',df_train.count())
print('train num entries:',df_test.count())#data partition (70% train, 30% test)
df_train, df_test, df_ignore = partition.train_test_val_split(data = df_remote,
training_percentage = 0.7,
testing_percentage = 0.3,
validation_percentage = 0)
print('train num entries:',df_train.count())
print('train num entries:',df_test.count())Entrenamos el modelo (random forest)
# RandomForestClassifier
key = 'ID'
label = 'ATTRITION'
features = ['AGE',
'BUSINESSTRAVEL',
'DEPARTMENT',
'EDUCATIONFIELD',
'GENDER',
'JOBROLE',
'MARITALSTATUS',
'OVERTIME',
'DAILYRATE',
'DISTANCEFROMHOME',
'EDUCATION',
'ENVIRONMENTSATISFACTION',
'HOURLYRATE',
'JOBINVOLVEMENT',
'JOBLEVEL',
'JOBSATISFACTION',
'MONTHLYINCOME',
'MONTHLYRATE',
'NUMCOMPANIESWORKED',
'PERCENTSALARYHIKE',
'PERFORMANCERATING',
'RELATIONSHIPSATISFACTION',
'STOCKOPTIONLEVEL',
'TOTALWORKINGYEARS',
'TRAININGTIMESLASTYEAR',
'WORKLIFEBALANCE',
'YEARSATCOMPANY',
'YEARSINCURRENTROLE',
'YEARSSINCELASTPROMOTION',
'YEARSWITHCURRMANAGER']
categorical_variable= ['EDUCATION']
def f_RandomForestClassifier(data, key, label,features):
rfc = RandomForestClassifier(n_estimators=1000,
max_features=3,
random_state=2,
split_threshold=0.00001,
max_depth= 8,
calculate_oob=True,
min_samples_leaf=1,
thread_ratio=1.0,
)
# Train the RandomForest Classifier
rfc.fit(data = data,
key = key,
label = label,
features = features)
return rfc
rfc = f_RandomForestClassifier(df_train, key, label,features)# RandomForestClassifier
key = 'ID'
label = 'ATTRITION'
features = ['AGE',
'BUSINESSTRAVEL',
'DEPARTMENT',
'EDUCATIONFIELD',
'GENDER',
'JOBROLE',
'MARITALSTATUS',
'OVERTIME',
'DAILYRATE',
'DISTANCEFROMHOME',
'EDUCATION',
'ENVIRONMENTSATISFACTION',
'HOURLYRATE',
'JOBINVOLVEMENT',
'JOBLEVEL',
'JOBSATISFACTION',
'MONTHLYINCOME',
'MONTHLYRATE',
'NUMCOMPANIESWORKED',
'PERCENTSALARYHIKE',
'PERFORMANCERATING',
'RELATIONSHIPSATISFACTION',
'STOCKOPTIONLEVEL',
'TOTALWORKINGYEARS',
'TRAININGTIMESLASTYEAR',
'WORKLIFEBALANCE',
'YEARSATCOMPANY',
'YEARSINCURRENTROLE',
'YEARSSINCELASTPROMOTION',
'YEARSWITHCURRMANAGER']
categorical_variable= ['EDUCATION']
def f_RandomForestClassifier(data, key, label,features):
rfc = RandomForestClassifier(n_estimators=1000,
max_features=3,
random_state=2,
split_threshold=0.00001,
max_depth= 8,
calculate_oob=True,
min_samples_leaf=1,
thread_ratio=1.0,
)
# Train the RandomForest Classifier
rfc.fit(data = data,
key = key,
label = label,
features = features)
return rfc
rfc = f_RandomForestClassifier(df_train, key, label,features)Guardamos el modelo entrenado en SAP HANA
# Creating an instance of ModelStorage MODEL_SCHEMA = 'MODEL_STORAGE' model_storage = ModelStorage(connection_context=cc, schema=MODEL_SCHEMA) rfc.name = 'RandomForest Classifier 1' model_storage.save_model(model=rfc,if_exists = 'replace')
# Creating an instance of ModelStorage
MODEL_SCHEMA = 'MODEL_STORAGE'
model_storage = ModelStorage(connection_context=cc, schema=MODEL_SCHEMA)
rfc.name = 'RandomForest Classifier 1'
model_storage.save_model(model=rfc,if_exists = 'replace')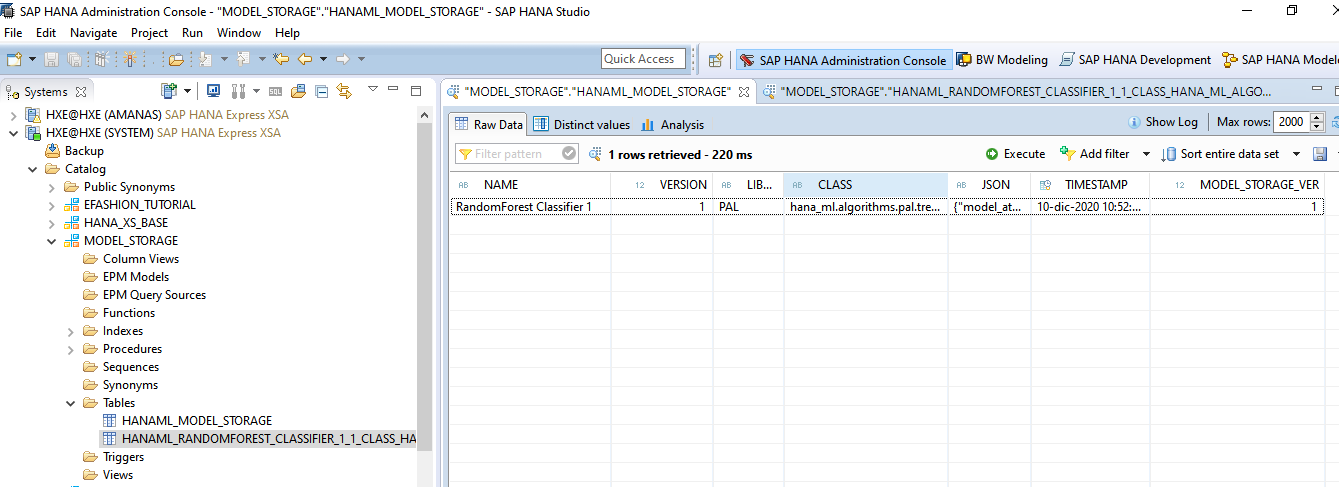
Realizamos la predicción y la guardamos en una tabla en SAP HANA
# Prediction
out = rfc.predict(data=df_remote,
key = key,
features = features)
# Save prediction on HANA Table
pd_out = out.collect()
dataframe.create_dataframe_from_pandas(cc2,pd_out,table_name = 'HR_ATTRITION_PRED', schema='PAL',force=True)# Prediction
out = rfc.predict(data=df_remote,
key = key,
features = features)
# Save prediction on HANA Table
pd_out = out.collect()
dataframe.create_dataframe_from_pandas(cc2,pd_out,table_name = 'HR_ATTRITION_PRED', schema='PAL',force=True)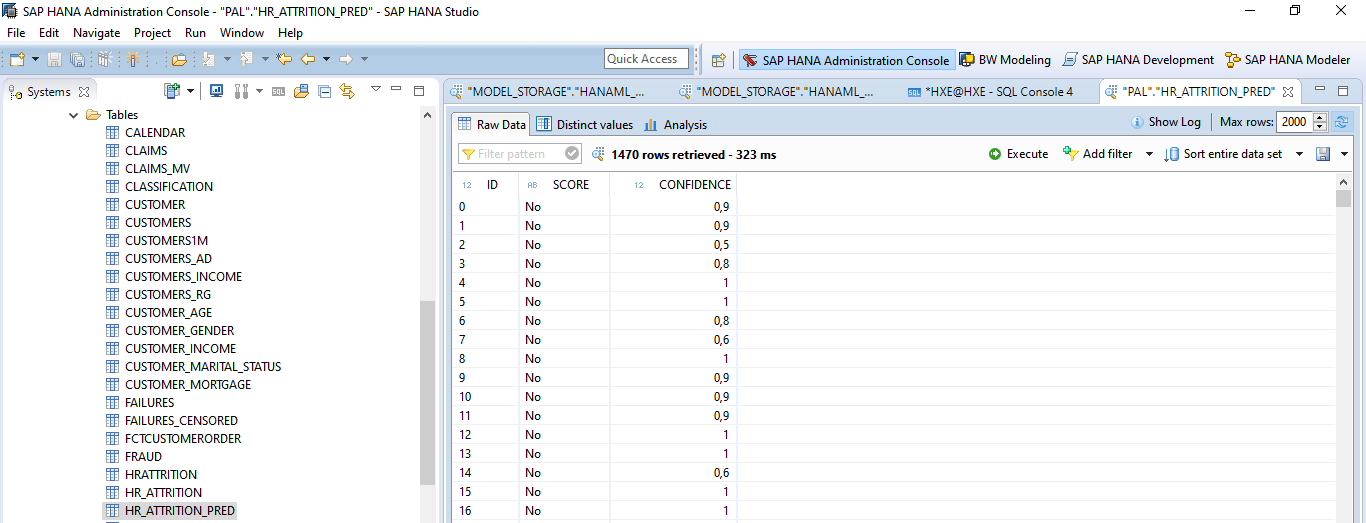
Creación de la aplicación web
Por defecto, HANA XSA permite desarrollar aplicaciones Java y NodeJS.Tambien es posible desplegar aplicaciones web en python generando un 'runtime' python utilizando un buildpack creado por SAP.
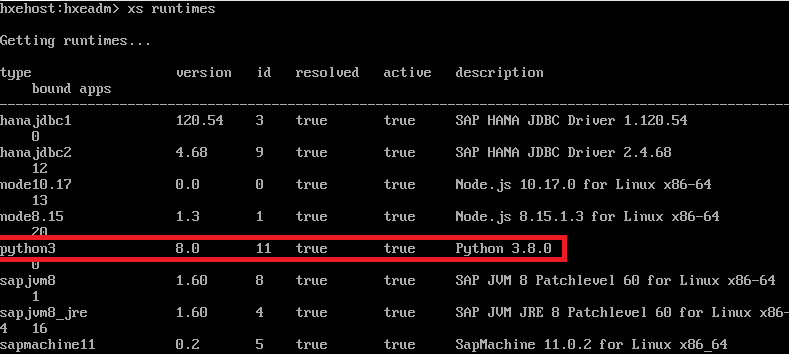
Una vez entrenado el modelo, he generado la apllicación web usando streamlit. Esta libreria de python es muy recomendable y permite generar aplicaciones web de machine learning de forma sencilla y en pocas lineas de codigo.
Para que la aplicación vaya mas rápido he cachea la conexión a HANA y la descarga del modelo entenado previamente. Despues de descargar el modelo, se realiza la predicción en función de los valores que el usuario ha seleccionado por pantalla.
import streamlit as st
#import pandas as pd
from pandas import DataFrame
from hana_ml import dataframe
from hana_ml.model_storage import ModelStorage
st.write("""
# Employee retention
""")
#Grid values
left_column, right_column = st.beta_columns(2)
with right_column:
# MONTHLYINCOME
MONTHLYINCOME = st.slider("Monthly Income",0,20000)
# AGE
AGE = st.slider("Age",18,65)
# TOTALWORKINGYEARS
TOTALWORKINGYEARS = st.slider("Total Working Years",0,40)
DISTANCEFROMHOME = st.slider('Distance from home',1,30)
with left_column:
# JOB ROLE
JOBROLE = st.radio('Job Role',('Sales Executive',
'Research Scientist',
'Laboratory Technician',
'Manufacturing Director',
'Healthcare Representative',
'Manager',
'Sales Representative',
'Research Director',
'Human Resources'))
# OVERTIME
OVERTIME = st.selectbox('Overtime',('Yes', 'No'))
EDUCATION= st.selectbox('Education',
('Below College','College','Bachelor','Master','Doctor'))
if EDUCATION == 'Below College':
num_EDUCATION = 1
elif EDUCATION == 'College':
num_EDUCATION = 2
elif EDUCATION == 'Bachelor':
num_EDUCATION = 3
elif EDUCATION == 'Master':
num_EDUCATION = 4
elif EDUCATION == 'Doctor':
num_EDUCATION = 5
else:
num_EDUCATION = 1
if left_column.button('Predicte!'):
#Create dataframe with grid values
key = 'ID'
columns=['ID',
'AGE',
'EDUCATION',
'JOBROLE',
'OVERTIME',
'DISTANCEFROMHOME',
'MONTHLYINCOME',
'TOTALWORKINGYEARS']
l_values = [{'ID': 0,
'AGE':AGE,
'EDUCATION': num_EDUCATION,
'JOBROLE':JOBROLE,
'OVERTIME':OVERTIME,
'DISTANCEFROMHOME':DISTANCEFROMHOME,
'MONTHLYINCOME':MONTHLYINCOME,
'TOTALWORKINGYEARS':TOTALWORKINGYEARS}]
pd_df = DataFrame(l_values)
features=['AGE',
'EDUCATION',
'JOBROLE',
'OVERTIME',
'DISTANCEFROMHOME',
'MONTHLYINCOME',
'TOTALWORKINGYEARS']
@st.cache(allow_output_mutation=True)
def Loading_model_from_HANA():
cc = dataframe.ConnectionContext(url,port,usr,pwd)
MODEL_SCHEMA = 'MODEL_STORAGE'
model_storage = ModelStorage(connection_context=cc, schema=MODEL_SCHEMA)
model_name = 'RandomForest Classifier 1'
model = model_storage.load_model(name=model_name,version=1)
return model,cc
model,cc = Loading_model_from_HANA()
hana_df=dataframe.create_dataframe_from_pandas(cc,pd_df,
table_name = 'HR_ATTRITION_APP1',
schema='PAL',
force=True
)
out = model.predict(data = hana_df,
key = 'ID',
features = features
)
t_prediction = out.select('SCORE').collect().values.tolist()
result = t_prediction[0][0]
if result== 'Yes':
st.success('Attention, the employee could leave the company :(')
else:
st.success('The employee will remain within the company :) ')import streamlit as st
#import pandas as pd
from pandas import DataFrame
from hana_ml import dataframe
from hana_ml.model_storage import ModelStorage
st.write("""
# Employee retention
""")
#Grid values
left_column, right_column = st.beta_columns(2)
with right_column:
# MONTHLYINCOME
MONTHLYINCOME = st.slider("Monthly Income",0,20000)
# AGE
AGE = st.slider("Age",18,65)
# TOTALWORKINGYEARS
TOTALWORKINGYEARS = st.slider("Total Working Years",0,40)
DISTANCEFROMHOME = st.slider('Distance from home',1,30)
with left_column:
# JOB ROLE
JOBROLE = st.radio('Job Role',('Sales Executive',
'Research Scientist',
'Laboratory Technician',
'Manufacturing Director',
'Healthcare Representative',
'Manager',
'Sales Representative',
'Research Director',
'Human Resources'))
# OVERTIME
OVERTIME = st.selectbox('Overtime',('Yes', 'No'))
EDUCATION= st.selectbox('Education',
('Below College','College','Bachelor','Master','Doctor'))
if EDUCATION == 'Below College':
num_EDUCATION = 1
elif EDUCATION == 'College':
num_EDUCATION = 2
elif EDUCATION == 'Bachelor':
num_EDUCATION = 3
elif EDUCATION == 'Master':
num_EDUCATION = 4
elif EDUCATION == 'Doctor':
num_EDUCATION = 5
else:
num_EDUCATION = 1
if left_column.button('Predicte!'):
#Create dataframe with grid values
key = 'ID'
columns=['ID',
'AGE',
'EDUCATION',
'JOBROLE',
'OVERTIME',
'DISTANCEFROMHOME',
'MONTHLYINCOME',
'TOTALWORKINGYEARS']
l_values = [{'ID': 0,
'AGE':AGE,
'EDUCATION': num_EDUCATION,
'JOBROLE':JOBROLE,
'OVERTIME':OVERTIME,
'DISTANCEFROMHOME':DISTANCEFROMHOME,
'MONTHLYINCOME':MONTHLYINCOME,
'TOTALWORKINGYEARS':TOTALWORKINGYEARS}]
pd_df = DataFrame(l_values)
features=['AGE',
'EDUCATION',
'JOBROLE',
'OVERTIME',
'DISTANCEFROMHOME',
'MONTHLYINCOME',
'TOTALWORKINGYEARS']
@st.cache(allow_output_mutation=True)
def Loading_model_from_HANA():
cc = dataframe.ConnectionContext(url,port,usr,pwd)
MODEL_SCHEMA = 'MODEL_STORAGE'
model_storage = ModelStorage(connection_context=cc, schema=MODEL_SCHEMA)
model_name = 'RandomForest Classifier 1'
model = model_storage.load_model(name=model_name,version=1)
return model,cc
model,cc = Loading_model_from_HANA()
hana_df=dataframe.create_dataframe_from_pandas(cc,pd_df,
table_name = 'HR_ATTRITION_APP1',
schema='PAL',
force=True
)
out = model.predict(data = hana_df,
key = 'ID',
features = features
)
t_prediction = out.select('SCORE').collect().values.tolist()
result = t_prediction[0][0]
if result== 'Yes':
st.success('Attention, the employee could leave the company :(')
else:
st.success('The employee will remain within the company :) ')I hope it will be useful for you and thanks for sharing!
Home